General UtilitiesApril 17, 2020(edited May 20, 2020)
This addon directory (keh_general) is meant to hold general use case scripts. In a way those scripts can be considered "sub-addons". What is available:
- encdecbuffer.gd: A class (EncDecBuffer) is defined in order to encode/decode variant data into/from byte arrays. This process is used mostly to strip out the variant headers (4 bytes) from properties primarily before sending then through networks. Because it may be useful for other use cases it became a separate addon.
- quantize.gd: Allows quantization of floating point numbers as well as compression of rotation quaternions using the smallest three method.
Script: data/encdecbuffer.gd
This script was born from the desire to automate the encoding and decoding of variant data into packed low level byte arrays (PoolByteArray). Now, why all this trouble? The thing is that variables in GDScript take more bytes than we normally expect. Each one contains a 4 bytes "header" indicating what type is actually stored within. When dealing with networks, this extra data may not be desireable.
So basically, the main reason for this addon is to simplify as much as possible the task of stripping out the variant headers and ultimately reduce the require bandwidth when dealing with networked games.
The basic usage of this class is to instance it then initialize the internal PoolByteArray with an initial data, either to be filled (encoding) or extracted (decoding).
This addon specific demo is found in the demos/general/edbuffer.tscn scene, which contains an attached script.
In order to begin using this, an object must be created:
func some_function() -> void:
# some code
var encdec: EncDecBuffer = EncDecBuffer.new()
# Initialize with some empty buffer so it can be filled
encdec.buffer = PoolByteArray()
From there, it becomes possible to fill the internal buffer using several of the provided functions, which will be described shortly. There is one thing to keep in mind though. When the object is created, it performs some calculations in order to initialize some internal values that are necessary to properly deal with the data. Ideally this information would be static, that is, initialized once and preferably shared between each instance of this class (if you know C++ then you understand what I'm talking about here). Unfortunately that's not possible with GDScript, so when profiling your code keep an eye on the instantiation of this class. What I would suggest if this becomes a problem is to put this object as a property of your script (instead of a function local) and reuse the internal buffer when necessary. In other words, avoid creating an instance of this class at every single loop iteration, otherwise it should be fine.
Following the previous snippet, the created object, encdec, is ready to be filled with data, which can be done through the various write_*() functions. The available options are:
| Function | Stored Bytes |
|---|---|
| write_bool() | 1 |
| write_int() | 4 |
| write_float() | 4 |
| write_vector2() | 8 |
| write_rect2() | 16 |
| write_vector3() | 12 |
| write_quat() | 16 |
| write_color() | 16 |
| write_uint() | 4 |
| write_byte() | 1 |
| write_ushort() | 2 |
As you can see, just a subset of the Godot types can be stored within the buffer. But to be honest, there is no need to expand on to other types, really! Nevertheless, calling one of those functions will basically append the relevant data into the internal encdec.buffer. There is another thing to note here. Two of those functions corresponds to types that are not exactly present in Godot, write_uint() and write_ushort(). In the how it works tab I talk a little more about those.
Anyway, to exemplify those functions, let's encode into the object one of each, assuming we have the provided variables and assuming there is a function named send_data() that receives one PoolByteArray as argument (be careful with the fact that byte arrays are passed as value, not as reference, meaning that they may become expensive to be given as arguments):
func some_function() -> void:
# some code, which may include the variables getting the desired values.
encdec.write_bool(some_bool)
encdec.write_int(some_int)
encdec.write_float(some_float)
encdec.write_vector2(some_vec2)
encdec.write_rect2(some_rect2)
encdec.write_vector3(some_vec3)
encdec.write_quat(some_quat)
encdec.write_color(some_color)
encdec.write_uint(some_hash)
encdec.write_byte(some_byte)
encdec.write_ushort(some_16bitnum)
# Send this encoded data somewhere else
send_data(encdec.buffer)
See how simple it was to just pack the data into the buffer? In the demo project there is a comparison of the data usage of this encoding and directly using var2bytes() function to store the same values. For further testing, the four compression methods (FastZL, Deflate, Zstd and GZip) provided by PoolByteArray were used to also compare the EncDecBuffer packing against the normal var2bytes() function.
Now, how about obtaining back those values? Those are done by the various read_*() functions and there is one corresponding to each of the write_*() functions. When one of those functions is called, the internal reading index is incremented by the corresponding amount of bytes, meaning that if you call the reading functions in the exact same order of the writing, you get everything back, as shown in the following snippet
func receive_data(data: PoolByteArray) -> void:
# Create the encoder/decoder object
var encdec: EncDecBuffer = EncDecBuffer.new()
# Initialize it's buffer with the received data
encdec.buffer = data
# Extract the values - it must be in the same order it was encoded
var some_bool: bool = encdec.read_bool()
var some_int: int = encdec.read_int()
var some_float: float = encdec.read_float()
var some_vec2: Vector2 = encdec.read_vector2()
var some_rect2: Rect2 = encdec.read_rect2()
var some_vec3: Vector3 = encdec.read_vector3()
var some_quat: Quat = encdec.read_quat()
var some_color: Color = encdec.read_color()
var some_hash: int = encdec.read_uint()
var some_byte: int = encdec.read_byte()
var some_16bitnum: int = encdec.read_ushort()
# Do some stuff with those extracted values
There is also a set of rewrite_*() functions, which gives the possibility to overwrite specific bytes within the buffer. As one use case example, suppose we want to store an arbitrary amount objects. When reading back we obviously need to know how many are there. So, before packing the objects we first write this amount into the buffer. But what if we only get the actual number of objects after iterating through a list? One possible solution would be to first iterate through the list, write the object count then iterate through the list again storing the objects in the process. For a rather small amount of objects it should not be a problem. Still, with the rewrite functionality, the solution becomes to first obtain the byte "address" where the object count begins, write a "dummy amount" into the buffer, iterate through the objects, storing them, and finally rewrite the object count, using the obtained "address". The following snippet showcases this:
# ... some code
# Obtain the "address" of the object count
var count_address: int = encdec.get_current_size()
# Write the dummy object count
encdec.write_uint(0)
# Use this to hold the object count
var obj_count: int = 0
# Iterate through the objects
for obj in object_list:
# ... some code
# Assume must_store() performs some tests and return true if the object is meant to be stored
if (must_store(obj)):
obj_count += 1
# Store the object within the encdec ...
# Now rewrite the object count
encdec.rewrite_uint(obj_count, count_address)
While this functionality is not used in the example code, the network addon does use it. Nevertheless, that all! This addon is that simple to use!
Internally this class deals with a buffer (in my inspiration pinnacle, I named it, er..., buffer), which is one PoolByteArray. When encoding, the overall process consists of stripping out 4 bytes of the given value and appending the rest into the buffer property. When decoding, take the data and append into it the relevant header. This will be shown with more details shortly.
For now, let's talk about one very special case. Unfortunately we don't have unsigned integers within GDScript. This brings a somewhat not so fun "limitation" to how numbers are represented.
The maximum positive number that can be stored in a 32 bit unsigned integer is 4294967295. Because GDScript only deals with signed numbers, the limit would be 2147483647. But we do have bigger positive numbers in GDScript, only that behind the scenes Godot uses 64 bit integers for those cases! In other words, suppose we want to send through the network a hashed string, which is meant to be 32 bits. If we directly send the returned value from the hash() function, we are actually sending 32 bits header + 64 bits value (not to mention some extra overhead related to how the packets are built to/from ENet). In the write_uint() function, this class strips out the excess bits (plus the header). This obviously assumes the value to be encoded is within the boundary [0 .. 4294967295].
The first thing that will be explained here is related to the internal values. Most of them are used to "cache" information that will be used during the encoding and/or decoding. So, let's go through them.
uint_start: when requesting to encode uint, the input variable may be stored in a 64 bit integer. This means a bunch of bits are meant to be discarded. This variable is meant to hold the starting position of the bits that must be stored in the buffer.fill_[x]bytes: when certain values are encoded, the discarded bits must be recovered when decoding them back from the buffer. These three byte arrays are holding exactly those bits, which are basically all 0 but makes things a lot easier when rebuilding the variants. In the case of the 4 bytes, it's mostly meant to recover the uint. For the 3 bytes, to recover boolean and single bytes. Finally, for the 2 bytes to recover ushort values.property_header: this is a dictionary that caches the stripped out header of the supported types. So when a values must be recovered, the basic idea is to take this header, append any of the "fill" arrays if necessary then append the stored data. With the header it's also stored the size, in bytes, of the corresponding type. Each of those are keyed by the type id of the variable.is_big: honestly I'm not sure if this is needed, but it holds true if the system is running in big endian and false if little endian.rindex: this is the reading index, which is used by the variousread_*()functions. In other words, when oneread_*()is called, data will be taken from the index specified in this variable and then it will be "advanced" by the amount of bytes used by that type. So, if you callread_uint(), after that the new index will berindex + 4.
Let's delve into the encoding process. All of the write_*() functions are actually wrappers around a generic function named encode_bytes(). This one requires the actual value to be encoded, the number of bytes that should be extracted and the starting position of the relevant data. To better picture this, consider the case for a simple integer value, 32 bytes. To convert that into a byte array we call var2bytes() giving the variable as input. We then get something like this:
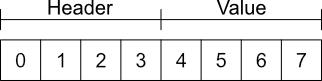
The numbers indicate the byte indices and, as you can see, normally the value begins after the header. We are interested in storing only the value and discard the first four bytes. So, for that, we call subarray() indicating that we only want the bytes at indices 4 through 7. So, in this case we would call encode_bytes(variable_name, 4, 4) (the first 4 is the amount of bytes and the second one the starting index of the data). This should give you have enough information to understand all of the write_*() functions!
As for the reading, there is also a generic function, named read_by_type(), which only requires the type id as input. Based on the requested type the function retrieves, from the cached property_header dictionary, the amount of bytes that must be extracted from the internal buffer. The function bytes2var() is then used to take a byte array and convert back into a variant. Now remember that in the buffer only the value has been stored, not the header, which is required data by the bytes2var() function. So the input given to this function is basically the value cached in the property_header plus the sub-array extracted from the internal buffer. The starting index is given by the rindex variable while the ending is calculated by the number of bytes that must be retrieved.
The majority of the read_*() functions call this generic read_by_type() function giving the relevant input for the specified type. The exceptions will be explained bellow.
read_bool(): the boolean type uses a single byte when stored in this buffer, but it actually uses header + 4 bytes when in a variant. This means it's necessary to take the header, the "3 bytes fill" and the actual stored value. So, in this case the generic function is not called because some extra data is necessary to rebuild the original variable. Note that in this case theis_bigis taken into account.read_uint(): for this case, the desired is to interpret the integer number as being unsigned, thus always positive. This means that Godot will use 64 bits for some numbers. TheEncDecBufferwill strip out the additional bits, provided the number is within the possible range of 32 bits. To restore the original variant those extra 4 bytes must be added to the array with the header. That's what the function does.read_byte(): this is the exact same case of the boolean, but uses the integer header instead of the bool.read_ushort(): when thewrite_ushort()is used, it stores only 16 bits of the original 32 of the integer. In other words, 16 bits were discarded. Those must be filled when restoring the original variant, which is still an "ordinary" integer.
Finally about the rewrite functions. Those are also based on a generic function named _rewrite_bytes(), which takes the value, the byte index, how many bytes to store and the starting index of the data within the original variable (much like the generic encode bytes function). The _rewrite_bytes() uses the set() function from the PoolByteArray(), which is the only function that allows overwriting something within the array. Because of that it's necessary to overwrite the data byte by byte. The idea here is to first feed the requested value to the generic encode_bytes() function in order to obtain an encoded byte array. After that, take each of the returned bytes and store into the buffer using the set() function, which requires the byte value and the byte index.
Script: data/quantize.gd
When the range of a floating point number is known, it becomes possible to quantize it into integers using smaller number of bits. This is a lossy compression as it's basically reducing the precision. On many occasions the incorporated error is small enough to be acceptable.
As an example, colors (Color) store the values in four floating point components but the values are always in the range [0..1]. Very small discrepancies in the color may very well be completely unnoticeable and thus, maybe acceptable to be compressed into a rather small number of bits per component. Another use case for this is the compression of rotation quaternions, with some extra techniques, which will be described in the how it works.
The entire functionality given by the class is done through static functions, meaning that an instance of the class is not needed to use anything in this addon.
To quantize a floating point number in the range [0..1], the function quantize_unit_float() is given. It requires two arguments. The value to be compressed and the number of bits which must be between 1 and 32. Note that 32 bits is not exactly useful in this case as it uses the same amount of bits of floating point numbers. An integer will be returned. Note that in this case it will still be a full 32 bit integer + the variant header. In this state it's not exactly useful, but the remaining bits can be safely discarded or maybe used to incorporate additional quantized floats.
To restore the float (still in the [0..1] range) there is the restore_unit_float() function. It requires the quantized integer data and the number of bits used to compress the original float. The return value is a float that should be close to the original one.
In practice it may look like this:
# Quantize a float in range [0..1] using 10 bits
var quantized: int = Quantize.quantize_unit_float(0.45, 10)
# ... some code
# Restore the quantized float
var restored: float = Quantize.restore_unit_float(quantized, 10)
In this case, restored = 0.449658. It does incorporate an error, which becomes smaller if the number of bits is increased.
What about different ranges? For that, there is the quantize_float() function, which requires 4 arguments. The first one is the float to be compressed. Then there are minimum and maximum values, respectively. Finally, the number of bits. It will then return an integer value, much like the quantize_unit_float() function.
To restore the float with arbitrary range there is the restore_float() function, which requires 4 arguments. First, the integer containing the quantized float. Then the minimum and maximum values, respectively. Finally, the number of bits used to compress the float.
So, suppose we want to quantize a float that goes in the range [-1..1], using 16 bits this time:
# Quantize a float in range [-1..1] using 16 bits
var quantized: int = Quantize.quantize_float(-0.35, -1.0, 1.0, 16)
# ... some code
# Restore the quantized float
var restored: float = Quantize.restore_float(quantized, -1.0, 1.0, 16)
This should result in restored = -0.349996.
That is basically all for simple floating point quantization! And as mentioned before, those functions can be used to compress components of rotation quaternions. The exact way this is done is explained in the how it works tab. The basic knowledge needed to understand the rest of the text in this tab is the fact that the compression here finds the largest component, drops it and compress the remaining components (hence the name smallest three). Nevertheless, a few functions are provided in this script just to make things easier.
The compress_rotation_quat() is a function provided to perform the rotation quaternion compression in a "general way". It requires two arguments, the quaternion itself and the number of bits per component. The return value is a Dictionary containing a few fields:
a,bandc: those are the remaining quantized components, basically the return value ofquantize_float()for each of those components.index: indicate which of the quaternion component was dropped (0 = x,1 = y,2 = zand3 = w).sig: while not entirely necessary, indicate the original signal of the dropped component (1 = positive,0 = negative).
Then there is the restore_rotation_quat() function, that requires two arguments. The first one is a Dictionary in the exact same format of the one returned by compress_rotation_quat(). The second one is the number of bits used per component. It will then return the restored Quat.
As an example, suppose we have a rotation quaternion named rquat and want to compress it using 10 bits per component:
# Compress a rotation quaternion using 10 bits per component
var compressed: Dictionary = Quantize.compress_rotation_quat(rquat, 10)
# ... in here we could pack the components of the returned dictionary into a single integer
# Restore the quaternion
var restored: Quat = Quantize.restore_rotation_quat(compressed, 10)
That's the basic idea. However, the returned dictionary may not be very useful. Indeed, each field of it is using a full variant object! Just the 3 components would be using 24 bytes (3 * 4 for the variant headers, plus 3 * 4 for the integers). This dictionary is meant to serve as an intermediary data and the compression only becomes useful when the result is packed into integers (as mentioned in the comment in the previous snippet).
To facilitate a little bit, there are 3 "wrappers" to compress rotation quaternions. Those use 9, 10 or 15 bits per component. The first two cases result in data that can be packed into a single integer, which is the return value of those two cases. 15 bits per component requires more than the 32 bits of a single integer. To that end, the function for this case returns a PoolIntArray containing two integers, one that is fully used and the other that can discard 16 bits. The functions in question are compress_rquat_9bits(), compress_rquat_10bits() and compress_rquat_15bits(). In all cases only the rotation quaternion is required as sole argument.
To restore those quaternions 3 functions are provided, restore_rquat_9bits(), restore_rquat_10bits() and restore_rquat_15bits(). In the first two cases only a single integer is required as argument, which should match the return value of the corresponding compress functions. The 15 bits case, however, requires two integers, which should match those returned in the array of corresponding function.
Because dealing with the 9 and 10 bits cases are pretty straightforward, I will show only the 15 bits in the following snippet. Regardless, suppose we have a rotation quaternion named rquat to be compressed using 15 bits per component:
# Compress a rotation quaternion using 15 bits per component
var compressed: PoolIntArray = Quantize.compress_rquat_15bits(rquat)
# In here compressed[1] can discard 16 bits
# Restore the quaternion
var restored: Quat = Quantize.restore_rquat_15bits(compressed[0], compressed[1])
That's basically how to use the rotation quaternion compression! Still there are two very important facts that must be kept in mind:
- Rotation quaternions can be flipped, that is q=−q, and they will still represent the exact same orientation. As part of the compression process, it's possible the signal of the components will be flipped in order to obtain the correct orientation. However, while not entirely necessary, the 9 bits and 15 bits compression functions use the bits that are still "free" to encode the original signal and restore them. However, the 10 bits compression does not have room for this and occasionally will result in "flipped quaternions". Again, they represent the same orientation but this information is somewhat necessary in case you want to directly compare restored quaternions against the original ones.
- As is, the returned data from most of the quantization functions will be rather useless. The thing is, those will still use the "full integer" bits, not to mention they are returned as GDScript variables, which are variants, containing extra 4 bytes (the headers). However bit masking can be used to pack/store the values as desired. And, if you see the previous script described in this page (
encdecbuffer.gd), you will probably notice how these two scripts can complement each other rather well.
The core of the quantization basically occur on quantize_unit_float() and restore_unit_float() functions. Those are used to perform the encoding and decoding of the floats into integers. Those require the range to be [0..1] (hence unit float).
Encoding (quantize_unit_float()) consists of first "distributing" the numbers into a fixed number of intervals (or "buckets"), which is defined by the amount of bits, then scaling the given float into one of those "buckets". To help create an even distribution the scaled number is then rounded to the nearest integer. The decoding performs the reverse operation.
But then, often arbitrary ranges are desired. This can be achieved by first normalizing the desired range into [0..1] then calling the quantize_unit_float() and restore_unit_float(). The normalization is performed by this simple calculation:
In here, n is the resulting unit float while v is the original value to be quantized. Interestingly, this is all about the floating point quantization!
Then there are the rotation quaternion compression functions. The method used here is often called smallest three, in which the largest component is dropped and the remaining three are quantized, then packed into integers through bit manipulations. Well, OK, this fact has already been mentioned a few times in this tutorial, but how does this work?
The basic idea here is that rotation quaternions have their length equal to 1, always. Translating this to math:
x2+y2+z2+w2=1With this in mind if we don't know one of the components (w for example), we can calculate it by using the following:
w=1−x2−y2−z2Again, this is relying on a property of quaternions representing rotations (that is, length = 1).
The range of each component should be [-1..1], but if the largest absolute component is dropped instead of a "fixed one" (like w, for example), we can reduce the range which, in turn, increases a little bit the precision of the quantization. Doing this means two things:
- In the encoding, the index of the dropped component must be included, which requires two bits (x = 0, y = 1, z = 2 and w = 3).
- The new range of the components must be calculated. In the excellent networking series by Glenn Fiedler, more specifically on Snapshot Compression, when the largest component is dropped, the range becomes [-0.707107..0.707107].
If you don't want to read the linked article, here is the important bit, related to the range calculation. When the largest component is dropped, the next one occurs when two components have the same absolute value while the other two components are 0. Because this is still a rotation quaternion, the length is 1. We don't exactly know which components are the 0 and which ones are not, so we can consider the non zero as a, for the next calculation. So:
a2+a2=1Developing this to find a:
a=21The result of this is the mentioned range (which in the script is defined as a constant named ROTATION_BOUNDS).
Before delving into the functions that perform the operations, there is one last detail that must be described. The equation used to restore the dropped component will always result in a positive number but if it was originally negative, it may not properly work. Interestingly, we don't have to encode the original signal of the dropped component. The thing is, rotation quaternions have another rather interesting property. Consider the rotation quaternion q. The property is basically this:
q=−qIn other words, if you negate each component of a rotation quaternion, it will still represent the exact same rotation! With this in mind, if the largest component is negative, then all of the other components can be negated in order to make the dropped component positive while still keeping the same rotation.
The core of the compression happens in the compress_rotation_quat() function, which requires the original quaternion and the desired number of bits per component. Because it's not possible to iterate through individual components of the quaternion using a loop, the components are added into an internal array. Once that is done, the index of the largest component must be located. Then that array element is erased. Finally, the remaining components are quantized using the quantize_float() function. Everything is then placed into a dictionary containing the necessary data.
Restoring the quaternion happens in the restore_rotation_quat() function. In here, each component is restored using restore_float() function. The dropped component is then rebuilt using the mentioned math expression (1−a2−b2−c2). Finally, based on the index of the dropped component, the quaternion is rebuilt using the restored values.
If you take a look into the two described functions, you may notice the fact that the original signal of the components is "restored" provided it's properly encoded in the dictionary (1 positive, 0 negative). While this is not really necessary, depending on the given precision (number of bits), it may result in enough room for this kind of encoding, so the information is provided for those cases.
The addon contains a few "wrappers" to use the quaternion compression to compress/restore quaternions in either 9, 10 or 15 bits per component without having to deal with the dictionary.
When dealing with 9 bits per component, 27 bits are necessary just for those quantized floats. Then 2 more are necessary for the index of the largest, dropped one. This means 29 bits are used. When dealing with integers we usually think about 32 bits and, in this case it means we have 3 unused bits. We have room to encode the original signal of the dropped component. If you take a look into the compress_rquat_9bits(), it takes the returned dictionary from the compress_rotation_quat() and packs the entire data into a single integer, using a bunch of bit masks (all of them defined as constants at the top of the script).
Restoring the quaternion using 9 bits per component basically unpacks everything back into a dictionary then calls the restore_rotation_quat() function.
The 10 bits per component version (compress_rquat_10bits()) does not have room for the original signal of the dropped component. In here, 30 bits are used for the quantized values plus the necessary two bits to encode the index of the dropped component. When restoring quaternions encoded with this precision, the restore_rquat_10bits() unpacks the values into a dictionary and, to ensure the restore_rotation_quat() works, it assigns 1 to the signal, meaning that it will preserve the signals of the encoded data. In other words, if the signals were flipped when encoding, then it will remain that way when decoded.
Finally, the 15 bits per component function (compress_rquat_15bits()) works a little bit differently. Just for the components 45 bits are necessary, which is more than the 32 bits given by a single integer. So the idea here is to pack two components into a single integer (30 bits) plus the index of of the dropped component, fully using that integer. A second one then encodes the remaining quantized value (15 bits). Normally we can deal with "short integers" (although not directly through GDScript), which means 16 bits. To fully use those 16 bits, the original signal of the dropped component is then encoded into the second integer. The two integers are returned in a PoolByteArray.
To restore the quaternion, the two integers must be given to the function (restore_rquat_15bits()), which will then unpack everything into a dictionary that will be used as input to the restore_rotation_quat() function.