Weighted Random Selection With GodotOctober 7, 2020
When working in a game we frequently want to randomly select something, be it to generate loot or maybe pick a random tile to generate levels. In this tutorial I show a method to randomly select something from a list but taking weights (different probabilities) into account. First I go over a tiny bit of theory then show the implementation in Godot using GDScript. After that I present some tips on how to use this technique on a few possible different use cases.
Note that for this specific tutorial I do not present any reference source code on Github simply because I don't think there is any need for it. However, if you want to see the technique in action I do have a demo in my Godot Addon Pack (more specifically the Inventory System demo) that do use it.
I also suggest reading this official Godot documentation tutorial on how to use its random number generator, which also include some use case examples.
Random Number And Distribution
Before going into any random selection I have to talk about the method typically used to keep a randomly generated integer number in the desired range, which is the modulus (%) operator, which in code is some_value = rand() % some_range. I have to mention it because this method is potentially bad (please, before you open Godot and make it generate thousands and thousands of numbers, measuring the resulting distribution, just to tell I'm wrong here, read the entire topic). There are three major factors that can affect the end result:
- The actual quality of the generator itself. That is, how evenly distributed are the probabilities of each number?
- The range of numbers that can be output by the generator.
- The desired range that is used to restrict the final resulting number.
It should be clear enough that if the generator itself is bad (1), the end result will indeed not be equally distributed. So, for the rest of the discussion in this topic let's assume that we always have a reasonably good random number generator (which is the case for Godot anyways).
Points (2) and (3) are directly "linked" and are behind the explanation as to why the modulus operator is potentially bad. To help with the explanation let's first define a few things:
- The maximum number that can be generated by
rand()asrand_max. - Because we have to count 0, we have
rand_max + 1possible numbers. Let's call this asrand_range.
One way to understand what that modulus operation is doing is basically that we have rand_range numbers to be divided into some_range boxes. From this point of view it should be clear that if some_range is a multiple of rand_range then it should not be a problem to divide the numbers through the boxes. However, the more some_range goes away from being a multiple of rand_range, the more uneven will be the distribution, always "favoring" the smaller numbers.
For a more concrete (extreme) example let's assume for a moment that rand_max is 9, meaning that rand_range is 10. If we decided to simulate a six sided die, then we would have 10 numbers to be divided into 6 boxes. The typical code for this would be something like roll = 1 + rand() % 6 (note that the 1 + doesn't change anything related to the final distribution). In this case, some_range = 6. The following image is meant to depict this example, where the squares are the "boxes" (the desired die faces) and the circles are the possible numbers that can be output by the generator.

This should make it clear that we can't evenly distribute that amount of numbers into the desired range and that we end up with more numbers being mapped into the smallest side of the range.
Let's take a closer look into some_range and see how its relation to rand_range can impact the end result, then we see what we can do about this. Remember that some_range tells us how many boxes we have to distribute rand_range numbers, or basically rand_range / some_range. In the image bellow I have placed the cases for some_range from 2 to 9 (each row is one value of some_range). Each column represents the available "box" for that some_range. Now notice the last column (after the "boxes"), where I have placed some very basic math. For each value of some_range there is a truncated division (rand_range / some_range) and the remainder of that operation.
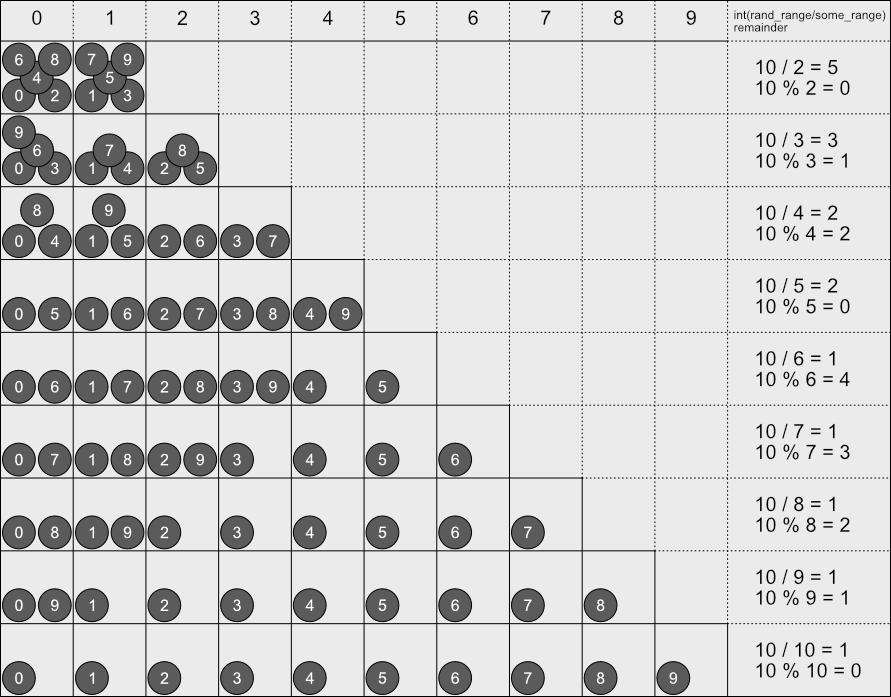
This image is meant to help graphically show what it going on. The remainder of the division basically tells us the "excess" numbers that will be generated without being able to complete the entire set of boxes (let's call this generated_excess). For instance, take a look at the 5th row (which is the six sided die example), where some_range = 6. In this case the remainder is 4. If you take a look at the boxes, four of them have one extra number. The truncated result of the division tells the minimum amount of numbers that are mapped into the available boxes which, for that row, is 1 (let's call this min_numbers_per_box).
Continuing with the six sided die example, still using this (weird) generator with max_range = 10. Each number has a one in ten (1/10) chance of being generated. But we already know that the die faces 1, 2, 3 and 4 have two numbers mapped into each, meaning that with this generator the chance of getting one of those values is actually two in ten (or 2/10 = 0.2). In other words, rolling a 5 or a 6 is much less likely than the expected, which are at the 1/10, 0.1 chance each.
Now let's assume our generator has max_range = 20 instead of just 10. In this case the truncated division (min_numbers_per_box) is max_range / some_range = 20 / 6 = 3 with remainder (generated_excess) 2. Each generated number has a one in twenty chance (1/20). Using the information for the division and remainder we know that the "boxes" 1 and 2 have one extra number, totalling to four. The other boxes have only three numbers. This means that faces 1 and 2 have actual chance of 4/20 = 0.2 each while faces 3, 4, 5 and 6 have 0.15 chance each.
Let's raise again the range of our generator. This time to 40 (skipping 30 because 6 is a multiple of that). The division is then 40 / 6 = 6 with remainder 4. We fall again into the first four boxes having an extra number mapped into them. That means, the die faces *1, 2, 3 and 4 have 7/40 = 0.175 chance each. However faces 5 and 6 have 6/40 = 0.15 chance each.
Did you notice that as max_range increases the difference in the probabilities become smaller? This happens because min_numbers_per_box increases while generated_excess remains "confined" into the some_range - 1 range. With all this information it should be clear that if some_range is small enough in comparison to max_range then this difference in the probabilities should not be that problematic.
The generated_excess basically tells us how many numbers can be generated in a way that will deviate the distribution from a uniform one. Using this we can calculate the total chance in which we will get one of those numbers. If the chance of a any single number is 1 / max_range, then the total probability of a "bad number" being generated is generated_excess / max_range;
A common solution to this problem is to first calculate the largest multiple of some_range that is less than or equal to rand_max (let's call it max_multiple). After that keep generating a number until it is smaller than max_multiple. What this does is basically discard any generated number that is in the excess list. If you take a look again into the 5th row, some_range = 6, this method would discard the generated numbers 6, 7, 8 and 9. In (generic) code it would look something like this:
max_val = max_range - (max_range % some_range)
roll = rand()
while (roll >= max_val)
roll = rand()
Now because Godot is used in this tutorial I have to delve a little into the specific details of the engine itself. For our six sided die we use randi(), which returns a random 32 bit integer number. Its rand_max is which is basically the biggest unsigned integer that can be represented with 32 bits. This puts our max_range = 4294967296! Yes, that's a rather big number. In other words, while the typical remainder method to restrict our desired range is not perfect, with a generator having this range it should not be a problem for the vast majority of use cases.
To put things in perspective, the min_numbers_per_box = 715827882 and generated_excess = 4. This means that the total chance of one of those extra numbers being generated and potentially cause a deviation in the distribution is basically 4 / 4294967296 = 0.0000000931%! Yes, I already multiplied that division by 100 to get the percent.
Still, I had to mention this potential problem because it does exist, albeit extremely mitigated by max_range of the generator available to us in Godot!
Simplest Random Selection
A very simple strategy to randomly select something from a list is to assign an incremental number for each of the items in that list. After that we use the random number generator to obtain a number and pick the object that has a number matching the generated one. Assuming the distribution of the generator itself is uniform the result of this approach should also be something uniform.
But this tutorial is about incorporating different probabilities of choosing items from the list, not having equal chances. For that, the simplest implementation involves manually setting ranges of numbers in a way to reflect their relative probabilities. After that use those ranges through a sequence of if .. elif .. elif .. else statements. Something like this (yes, I know, this is not exactly a real programming language, but I think the overall logic is shown):
// Assume rand() returns something between 0 and 1 and is uniformly distributed.
roll = rand();
if (roll < 0.7)
// pick stuff with 70% chance
else if (roll < 0.9)
// pick stuff with 20% chance
else
// pick stuff with remaining 10% chance
It's very simple to be implemented, however there are a few problems with it. What if we want to adjust the probabilities of the rarity ranges? In this specific case we have to ensure the adjusted values add to 1. It should not be that problematic for just 3 ranges, but still, it is a possible source of bugs. But, most importantly, what if we want to add more things into the list? As an example, what if we had a table of several swords that could be dropped as loot? Then, what if we wanted to add more swords as content patches? Or maybe the players are complaining about the drop rates and we have to tweak those ranges? Or what if we wanted to dynamically change those probabilities based on certain events happening in the game (maybe a lucky system and so on)?
Indeed, this technique does not scale very well and can easily become a burden to maintain! What if we could "automate" the process? Well, actually we can, sort of.
Interval Weights Array
Before I go into explaining the technique that prompted me into writing this tutorial, I have to mention another powerful one named the alias method. It is not the one I'm going to explain here simply because I frankly don't think we need something like that. Still, if you want a very detailed description of it, you can check here. What I will present here is fast enough and is extremely simple to be implemented (and easy to understand). The alias method requires a bit more code and, when compared to the technique here, is not that straightforward to understand. With that in mind, let's continue...
If we take a look again into the snippet given in the previous topic, it should be clear that what it is doing is basically setting intervals (which I called "ranges" in that topic) of numbers, sort of taking an area and dividing it into ones corresponding to their relative probabilities. The idea is to somewhat perform this area division in an "automated" way without having to change the code if we need to tweak some probability or add more stuff into the game.
The idea here is to break the algorithm into two major parts. The first one performs the initialization, which basically assigns the intervals to the objects within the list. This initialization can be performed only once if the weights don't change while the game is running. The second part is the random selection process.
The first thing that must be done is that each object must have a weight associated with it. Normally this is assigned in a database or even a spread sheet (which is then exported as comma separated values) and then somewhat imported into the game. This weight represents the relative probability between the items, which I will call roll_weight. Then the initialization part of the algorithm can be done. For each object that can be picked:
- Take current object's roll_weight and accumulate it (just sum) in a variable that was set to zero before the iteration. Let's call it total_weight.
- Use current value of total_weight and assign it as an extra value associated with current object. Let's call it accumulated.
That's it. The initialization is complete! Please note that the total_weight must be held somewhere because it will be used when picking an object, which is the second part of the algorithm, which goes like this:
- Generate a random number between 0 and total_weight. Let's call it roll.
- Search through the list of objects for the first one where its accumulated is greater than roll.
One very interesting thing here is that the total sum doesn't have to be equal to 1.0.
To illustrate this algorithm, suppose we have 6 items, A, B, C, D, E, and F (I know, not very creative object names, but at least they are generic enough) with weight 1.0 assigned to first four items, 0.5 assigned to E and 0.1 assigned to F.
After running the initialization we would end with something like this:
| Item | Weight | Accumulated |
|---|---|---|
| A | 1.0 | 1.0 |
| B | 1.0 | 2.0 |
| C | 1.0 | 3.0 |
| D | 1.0 | 4.0 |
| E | 0.5 | 4.5 |
| F | 0.1 | 4.6 |
The total_weight is then 4.6, which means that we have to use the random number generator to give us a number between 0 and 4.6. Continuing with the example, suppose the generator gave us 3.1. The first item where its accumulated is greater than or equal to 3.1 is D, which is 4.0. So, at this point the random picking would "choose" D.
With this technique, if you want to know an item's individual probability to be picked, all you have to do is divide its weight by the total_weight. The previous example of 6 items would be something like this:
| Item | Weight | Probability |
|---|---|---|
| A | 1.0 | 1.0 / 4.6 ≈ 0.21739 |
| B | 1.0 | 1.0 / 4.6 ≈ 0.21739 |
| C | 1.0 | 1.0 / 4.6 ≈ 0.21739 |
| D | 1.0 | 1.0 / 4.6 ≈ 0.21739 |
| E | 0.5 | 0.5 / 4.6 ≈ 0.10869 |
| F | 0.1 | 0.1 / 4.6 ≈ 0.02174 |
Because of rounding errors while "truncating" the values to be displayed here, if those numbers are directly used to check if the total is 1.0, you will actually get 0.99999. That's why I have made it explicit that those probabilities are approximate values!
Lastly I have to talk about the second step of the second part of the algorithm. Notice that I have said "search through". For a reasonably small number of items a linear search (simple iteration) should be enough and not problematic. However, if you have a somewhat bigger number of items to be chosen, then a binary search algorithm would be much better for the lookup. Now note something interesting here. The binary search requires that we have a sorted list in order to work. During initialization, the accumulated value is incrementally calculated, meaning that the list will indeed be correctly sorted. In other words, the premise for the binary search to work is already ensured during the initialization.
Implementation
As promised, sample GDScript code implementing the technique described. Suppose we have an array named object_types holding dictionaries in it. Assume each one of those entries have at least the following fields:
roll_weight: A value that could be retrieved from a database or something, indicating the relative probability in which this object should be picked.acc_weight: Holds the accumulated weight, which will be assigned during the initialization.
We also have another property named total_weight that is meant to hold the total sum after initialization, which looks something like this:
func init_probabilities() -> void:
# Reset total_weight to make sure it holds the correct value after initialization
total_weight = 0.0
# Iterate through the objects
for obj_type in object_types:
# Take current object weight and accumulate it
total_weight += obj_type.roll_weight
# Take current sum and assign to the object.
obj_type.acc_weight = total_weight
Ok, the initialization is done. At some other moment we want to randomly pick an object from this array. A function to do that could look like this:
NOTE: In Godot 4
rand_range()has been renamed torandf_range()
func pick_some_object() -> Dictionary:
# Roll the number
var roll: float = rand_range(0.0, total_weight)
# Now search for the first with acc_weight > roll
for obj_type in object_types:
if (obj_type.acc_weight > roll):
return obj_type
# If here, something weird happened, but the function has to return a dictionary.
return {}
As you can see, the implementation is extremely simple! Adding more object types will not change any of those two functions! And so will be the case if the roll weight is changed on any of the objects. All that have to be done in either case is run the init_probabilities() function before picking an object! Again, if you want a practical example, on my Godot Addon Pack I used this method to generate "random loot" within the inventory system demo.
Some Use Cases
This topic is meant to give some extra information on possible ways to use this technique for some possible use cases. Note that whatever I tell here is not necessarily the way to implement things, but a way.
Another thing to keep in mind is that I can't exactly give extremely detailed information or even any code, simply because most of the uses cases described bellow pretty much depend on the game project itself. But hey, this tutorial is about weighted random selection which has already been explained!
Random Loot
So the game is meant to generate loot as the player kills monsters or opens chests. The first obvious thing is that we must roll how many items will be generated. This should be a very simple roll (randi() % max_amount) and there isn't much to talk about. Then for each item to be generated we first determine the type of the item. So, we assign a roll weight to each item type then run the described algorithm. Then, maybe we can after that run it again to pick random stats to be "attached" to the item.
In a database we can have a table for each item type, assigning a roll weight to each one of those. Then, for each item on each table we also must have a column to specify the roll weight of that item. Then we need a database of item stats somewhat associated with that item type. And each stat may have a roll weight.
How about item rarity? Well, that pretty much depends on what rarity does to the item. On some games rarity just change the amount of stats that can be rolled and added into the item. In this case it's possible to have a table of rarities where each row holds its weight. This table can also hold information regarding the minimum and maximum amount of stats for that rarity. Those values can be directly plugged into randi_range() to calculate the amount of stats that must be rolled var roll_stats: int = randi_range(min_stats, max_stats).
But what if one of the rarities is meant to represent items that are not formed by random stats, like unique items? Well, in that case we need yet another table to represent those items. Each row needs information regarding the item type, its own roll weight and so on. So, in case the game needs this kind of scenario, then maybe for each item to be generated the first thing to be done is determine its rarity then proceed according to the result of this roll.
Loot Tables
On occasions we may want to restrict the type of loot that can be generated on certain areas of the game or even the actual monster type dropping the items. The easiest here is to create tables containing information related to the loot that can be generated. Those tables can then be associated with the areas and/or monsters.
The exact information on those tables is pretty much game dependant but, as you may guess, the roll weights have to be there. Usually this type of table would have information pointing into data present on other tables in the database, like item type and so on.
Depending on the design we may even assign multiple loot tables to specific monsters, like bosses for example. Suppose for instance that we want to ensure that a given boss will always drop one of a few items. We create a table with those items and assign the table to that boss. When generating the loot we ensure that we always pick one item from that table. Then we can have another "generic" table holding the "common" loot that will additionally drop from that boss. We can even go crazy and put roll weights on those tables and select one of them during loot generation!
Level Generation
The nice thing about this technique is that it can also be used as part of random level generation! Tiles can have roll weights associated with them. Based on the previous generated tile we can sort of restrict which type should be picked next in order to properly merge with that existing one.
In this case we obviously need some kind of tile database to easily initialize and run the picking function. This database would require manual input when adding the assets into the project and would probably greatly benefit from a simple plugin tool to help with this task.
Now keep in mind that this is meant only to be part of the random selection of the tile itself. The level generation algorithm is possibly way more complex. The thing is, if it remains completely random, the result will most likely not look natural or worse, like obstacles blocking passage to the main objective.
Dynamic Weights
What if we want to dynamically change the weights based on certain events in the game? Maybe we want to completely shift the weights of the item tiers based on the level of the player, always keeping the most appropriate tier with the highest weights. Or maybe the player equipped an item that increases the chance of rarer items to drop.
Again, what those weights will become and what exactly will be done to calculate them is completely project dependent. But, the interesting thing is, in practice most likely we will not have amounts of entries in a table that would result in a problem to simply re-calculate the accumulated weights as the events occur in the game. If we restrict the recalculation to be performed only when the events occur, things should run pretty much smoothly.
Disabling Objects
Suppose for some reason that we want to disable an item from being picked. Maybe we want to disable high tier items from dropping when the player is low level. Or, a bug is found with an item and the actual fix could take some time but, to avoid further problems the short term solution would be to simply disable that item. For that all we have to do is set its roll weight to 0.
Now to explain why this works, let's see the two possible situations:
- The item in question is the very first in the array. When that happens, the accumulated roll will be 0 since its weight is 0. Even if roll is zero, the
item.accumulated > rollwill return false and the search will continue. - The item in question is not the first one. Its accumulated will be exactly the same of the previous item, meaning that if the criteria to end the search is not met on the previous one, it will also be the case for the "disabled" item too, meaning that the search will continue.
Multiple Weight Arrays
In the previous topic I did mention about having multiple tables that would result in multiple arrays of accumulated weights. While we can't exactly go away from having multiple arrays, we can have generalized functions to perform the initialization and object picking. So, to end this tutorial I would like to present those functions.
Because arrays are passed as reference we can easily update their contents, which is necessary in order to update the accumulated weights.
# Returns the total accumulated weights, which should be used when randomly picking an object from the array
func init_probabilities(weights: Array) -> int:
var total: float = 0.0
for obj_type in weights:
total += obj_type.roll_weight
obj_type.acc_weight = total
return total
# Randomly pick an object from the given array. Assume the entries are dictionaries.
# Also, remember, if the size of the array is big it would be better to implement a binary search instead of linear
func pick_random_object(weights: Array, total_sum: float) -> Dictionary:
var roll: float = rand_range(0.0, total_sum)
for obj_type in weights:
if (obj_type.acc_weight > roll):
return obj_type
return {}
Assuming we have arrays and total weights, we can easily use those functions like this:
# Initialize the probabilities for item rarity and item type tables
total_rarity_sum = init_probabilities(rarity_weights)
total_item_type_sum = init_probabilities(item_type_weights)
...
# Randomly pick the rarity of the item
var rarity: Dictionary = pick_random_object(rarity_weights, total_rarity_sum)
var item_type: Dictionary = pick_random_object(item_type_weights, total_item_type_sum)
# Do something with the information obtained...
Final Words
And that is pretty much it! I truly hope you find this information useful! Now, please remember that for the majority of cases in games the algorithm described here is enough! When the list of possibilities within the table start to become large, binary search may be necessary instead of the crude linear search that I have shown here. On all cases, profile to check if the code is a bottleneck or not!
And if the table becomes really large, some people may argue that a better technique must be used and, for that I have already mentioned the alias method with two links to places that describe it.
Happy forging!